Software companies and other business services organizations almost universally underestimate the importance of a B2B customer data model.
For all the hype around customer 360 and customer data unification – even b2b customer data platforms are having a moment – very few operations and data teams can produce a conceptual or systemic view of how customers interact with their organizations.
This needs to change.
What is a B2B customer data model?
The B2B customer data model is the first step in the process of creating a unified customer experience. It maps where customers interact with your business, and who in your business interacts with those customers, and how that data is processed and managed.
An effective customer data model accounts for the day-to-day work of everyone from marketers and sellers to support and success teams, even product managers.
Without it, entire companies will have a very difficult time understanding how to provide a complete, on-brand, holistic customer experience.
But with it, your teams will be many times more effective and efficient in their work with customers.
Why are B2B customer data models so important?
Data is the only way your customer experience truly scales as you grow.
Think about it: imagine if your sales, marketing, customer success, finance, product and operations teams all had to join a call any time a question came in from a customer. Each had paper notes about that customer’s history with the business. So the only way for everyone to understand their role was for everyone to jump on a call together.
This is laughable because it is horribly inefficient.
But if your teams are not working on top of a strong foundation built using a B2B customer data model, there is little difference from the scenario above.
Perhaps instead of a meeting, they’ll just Slack their questions to other teams.
A fintech example: what happens without a B2B customer data model
Let’s take a real world example. A fintech company with 1,000 employees and a global presence has a dual customer acquisition funnel: the typical sales funnel (full of meetings and opportunities and emails and calls) and a compliance funnel (involving a compliance operations team that audits businesses to confirm legitimacy). To efficiently manage communications in the sales funnel, the company employs a bulk email sender, streamlining outreach efforts and ensuring effective communication across diverse markets.
But the compliance system is a custom tool, built in-house. The operations team uses it, and also works out of Zendesk for communications. This is separate from Salesforce and HubSpot where the marketing and sales teams live. Also sales and marketing have very restricted access to Salesforce, and no access to Zendesk or the compliance system.
When a business who has applied for an account asks about the status of their application, they ask sales. Sales sends a Slack message to the compliance team. The compliance team checks their compliance system, and runs a SQL query to double check the customer data warehouse. Then compliance returns to sales with a message about the status of the application. Sales responds to the customer. Turnaround time? 2-24 hours.
Without a customer data model, the customer experience is choppy, slow, confusing and frustrating.
When you don’t have a B2B customer data model, your customers suffer.
But so do your teams.
Ask any customer success or support leader what it’s like to have to run a SQL query to (hopefully) get complete information about a customer’s last several interactions with the product. Or how frustrating it can be to try to serve customers well, when they’re still having meaningful interactions with sales and marketing that aren’t tracked in or synced with the support tool (e.g. Jira or Zendesk).
Related: Demostack Develops a Customer 360 View Using Syncari
The same is true for marketing and sales, even finance. In many companies, when someone asks “how can I get a clear view of this customer or this segment of customers?” the response is “do you know SQL?” (True story, happened to me in two large startups).
You can change this for your organization.
Before we get started building a B2B customer data model…
At this point you probably have some questions or even objections.
Can’t I just use the customer data model inherent in my CRM?
If you let the tech guide you into a data model, a few problems inevitably occur.
- First, you’ll have no control when you need to make new relationships between different data types. Like adding a product or unbundling billing accounts. You’ll be stuck with however Salesforce or HubSpot or Zoho or Dynamics 365 or Oracle or SAP or FreshSales (Freshworks CRM) view the world.
- Second, the rest of your tools don’t fit that model. This means that the data in those tools will get left behind, because you’ll be optimizing the data quality in your CRM and neglecting the data quality in your sales engagement, support, finance and marketing tools.
Why start with a data model instead of a customer experience framework or customer journey map?
You can start with those too. If you’re operating right now with a clear understanding of your customer lifecycle, that’s going to make it difficult to know where to focus resources for growth.
In fact you need both a framework for interactions (customer lifecycle, customer journey, or customer experience framework), and an underlying data model, in order to develop the right layers of systems to support the universe of possible interactions.
But most companies stop at lightweight customer journey maps, and fail to build the data model that supports it.
The reality is, you have a customer data model right now, whether or not you’ve articulated it on paper. It’s time to take control of the situation. This is just like you have a customer lifecycle that customers reflect back to you – you just may be at various stages of wrapping the organizational head around it.
What is the difference between a “customer data model” and a generic data model?
At its simplest, a customer data model has a customer at its center. It exists to help businesses, with all their clunky moving parts, to interact smoothly and wisely with customers.
It’s important to remember that customers don’t see themselves as many bits of info in many different systems. They are one person, interacting with one brand. Any glitch in the consistency of their experience with your brand can ruin the relationship.
How many of us have tweeted angrily to an airline? Are all airlines equally instrumented for handling Twitter mentions and messages? No, you need both a social listening tool (like Cision or Brandwatch) for untagged mentions, and a social media management tool (like Sprinklr or Meltwater) that integrates with a support tool for tracking tickets handled via social channels. And you need a tool to then resolve those people identities from social channels with other systems (this is typically a CDP like Segment in B2C scenarios, though some tools like Sprinklr have grown to take on this aspect of the data layer, and even the listening component as well).
What is the difference between a B2C customer data model and a B2B customer data model?
There are two rather unique aspects of B2B vs. B2C data modeling.
The first is this idea of an “account” or a “company” – when you sell to businesses, you sell to legal entities rather than consumers. In other words, even if an LLC has one employee, your financial and legal relationship is with that company, not that employee. In other words, even if a limited liability company (LLC) has one employee, your financial and legal relationship is with that company, not that employee.
This means the data must accommodate the relationship between company staff and the company itself.
On the other hand, most B2C companies do not even record the employer of their customers. They simply transact with individuals.
The second aspect that makes B2B unique is the involvement of relationships. This idea of “owners” in your team that map to individuals at companies is crucial to your success. It also is very difficult to handle from a data standpoint.
Even product-led-growth companies tend to maintain a healthy level of relationships with their users and customers. Whether the title is sales or customer service does not matter: the point is that knowing someone at a company helps re-personalize the legal-entity-to-vendor transaction.
Who typically builds a B2B customer data model?
This varies wildly depending on who is in charge of maintain the accuracy and quality of information about customers in a given organization.
However, this tends to be at least two people in any business – one from the revenue or go-to-market (GTM) side of the business, and one from the product side.
Therefore, if your title is revenue operations, sales operations, marketing operations or even customer success operations, you probably could or should be leading the development of a B2B customer data model.
And then, if your title is head of technology, head of data, product lead, or growth product manager, you should be pushing for a coordinated effort in this domain as well.
How to build a B2B customer data model
I remember when I first saw a real sales and marketing data model built by a true marketing systems architect. It was fascinating and intimidating.
But again, without a cohesive approach to the data, how can we expect to deliver a consistent customer experience?
So let’s start with the basics.
Step 1: Determine your B2B customer data entities and objects
The first thing to do is understand the primary entities involved. An entity in a data model is the basic “object” of your data. In other words, if an entity exists, you can look at a list (or table) of all things under that classification.
For instance, if Contacts are an entity in a CRM, then you can look a list of all Contacts. When you do this, you’re working with a table of objects, where each object is the Contact entity type.
Below is a (mostly) comprehensive list of B2B customer data entities:
- Common Person Entity Objects
- Lead: Typically a new person who is just beginning to meaningfully interact with your business, or whose company is unknown.
- Contact: A person at known company, particularly if that company is a customer.
- Billing Contact: A person who handles contract and payment arrangements for a company.
- User: A person who logs into an application and uses it.
- Common Company Entity Objects
- Account: Typically a CRM term for companies.
- User Account: A way of tracking app usage at company level.
- Billing Account: An ERP or accounting term for companies.
- Other Common Objects
- Campaign Object: A marketing or sales activity set, that could include anything from a marketing email newsletter to an SDR outbound email sequence, from a form on a website to an imported list of companies with certain attributes.
- Opportunity Object: A possible deal with a company, usually with a primary contact or champion at the company.
- Product Object: A product, set of features, or individual feature you sell.
- Support Ticket Object: A request for support, opened by your team or by the customer.
- Financial Objects:
- Order / Order Item
- Quote / Quote Line Item
- Contract / Contract Line Item
- Common Event Entity Objects: Any action taken by a person
- Activity: Typically an action taken by representative at your business, such as an email from a Sales Development Representative (SDR) to a contact.
- Interaction: This could refer to clicks on an email, navigation on the website, downloading a PDF, or any other customer-side activity.
- Behavior: This could apply to in-app product usage events.
- Conversions: A sales or marketing conversion event, such as a signup, demo request, meeting held, or opportunity created.
- Transactions: Typically an event where payments or contracts are involved.
- Your Team: These are not always reflected in data models, but I recommend laying them out and how they’ll relate to the objects in your model.
- Sales Owner:
- Account Executive Owner
- SDR Owner
- Account Management Owner
- Customer Success or Support Owner
- Finance Admin Owner / Billing Owner
- Compliance Owner
- Legal Owner
- Sales Owner:
In a typical data model, each object sits in a box, with at least the actual database name and a unique identifier used to relate it to other objects.
Step 2: Lay out your entities and objects on blank space, and classify by entity type
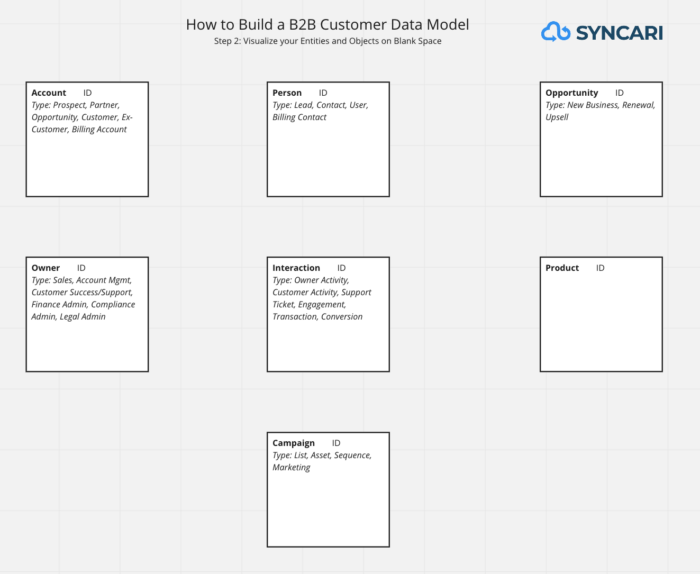
This could be a Miro board or any diagram solution, an Airtable base, or even a blank piece of paper.
Visit the Miro board shown in the screenshots throughout this article.
There is no need to arrange them in any particular order, yet. The important thing is to record the objects, color code or somehow reflect their entity type, and record any crucial attributes you want to note on each object as you begin.
Under each object, write “ID” and a related unique identifier. The ID will be inherited from systems storing these objects. There will be different IDs for each system.
For contacts, email is the most common unique identifier. This works great as long as the email is unique to that individual, and not a group or shared inbox. …And as long as it’s a real email. …And as long it’s a business email. …And as long as no one enters false information.
For companies, web domain is the most common unique identifiers. This too works great, as long as the company has one primary web domain. Companies that have gone through mergers and acquisitions often have multiple websites.
Step 3: Describe and classify relationships between objects
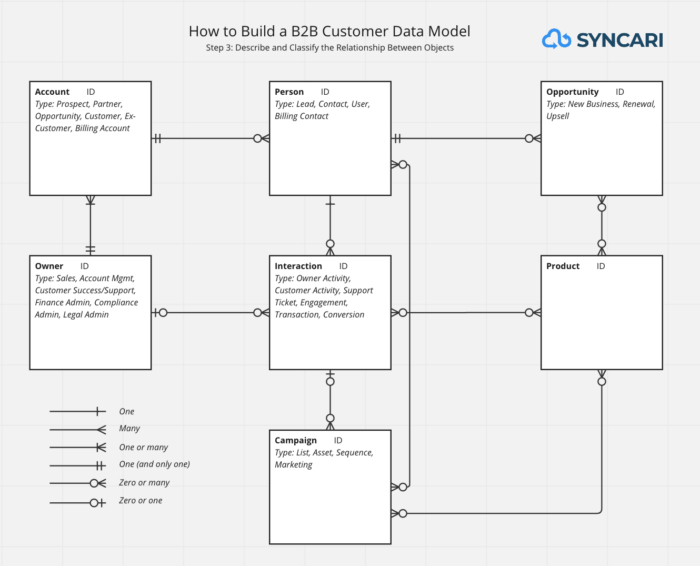
This is probably the most difficult step. It helps to learn a bit about relational models, but this gets very technical very quickly.
Suffice it to say: each object has at least one relationship to another object. Leads, for instance, can have a many-to-many relationship with Campaigns. This means one Lead can be part of many Campaigns, or many Leads can be part of one Campaign.
Once you have your objects laid out in front of you, start with the obvious ones. These might be…
- Lead to Campaign: many-to-many (leads are part of one or more campaigns).
- Account to Contact: one-to-many (accounts have multiple contacts, not vice versa). Note: it’s worth reflecting on how this is changing thanks to LinkedIn’s schema, which lists multiple companies as current roles, and the only way to clarify full time employment vs. an advisory role or community membership is to check the title and even to shortlist the name of companies; so don’t get too excited when those “Pavilion” leads come through the door.
- Account to Opportunity: one-to-one or one-to-many. This depends on how you sell. If you close “accounts” at a time, you want a one-to-one. Once an opportunity is closed, however, a new opportunity can be opened up. But some tools can be adopted separately by multiple people in an organization, in which case you’ll need one-to-many.
- Opportunity to Contact: one-to-many.
- Owner to Activity to Contact: one-to-many-to-one.
Step 4: Determine which systems contain which objects
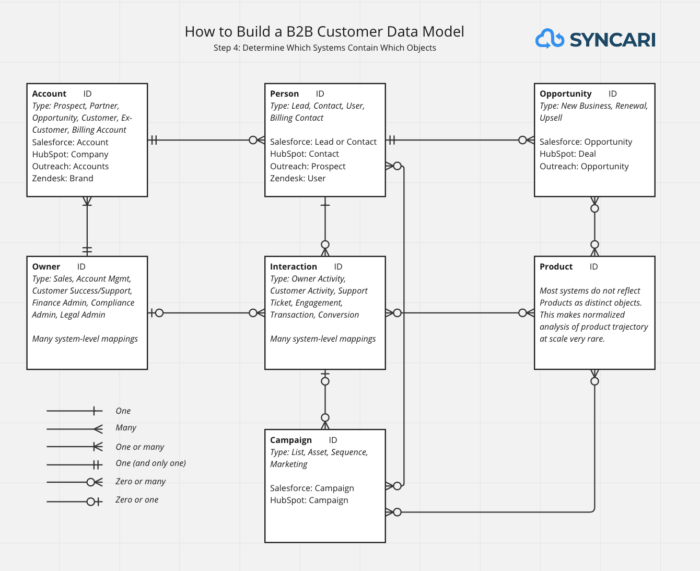
Record the name of the tools that house each object, and how it is referred to within those systems. For instance, Salesforce calls companies “Accounts” and HubSpot calls them “Companies.” Outreach only has “Prospects” for people despite the fact that Salesforce has “Leads” and “Contacts.”
This will also reflect back to you which systems need to be synchronized for which objects.
Step 5: Determine how those systems will communicate

Now that you know which systems need to be unified for specific objects, you can determine the best path to ensure these objects are unified across the customer journey.
There are important aspects to consider, given your newfound understand of your customer data.
- ID Stitching and Cross-System Unification: You need a tool that orchestrates object IDs across systems, such as an Contact ID in HubSpot that maps to a Contact ID in Salesforce that maps to a Contact ID in NetSuite.
- Dynamic Rules-Based Data Merge and Deduplication: You need a tool that can run deduplication and merge programs across all systems based on the logic you provide.
- Uptime Problems: You need a data platform that can manage attributes of your data in all systems through a stateful approach. This means that if one of those systems goes down, the data platform will hang on to the changes that should have been made while the end system was down, and update those records once it is back online.
- Data Lineage: You can think of data lineage like a “change log” that tracks all changes made to a record. Without it, mass overwrites can cripple your data quality in minutes, and there is no recourse. With it, you can revert to previous conditions if something goes wrong.
Here are some of your options for facilitating a unified customer data model, and therefore a consistent customer experience:
Native Connectors are Cheap but Limiting
Pros: Cost is the primary factor that drives companies to choose native connectors over 3rd party tools, or “middleware.” You already have a CRM, why not use its native integration with your customer support tool?
Cons: Native connections work great – when all you have is one pathway to sync. But there are two common problems with native connectors:
- You need to unify more than two systems. Native connectors don’t do this (unless they’re built on Syncari Embed of course).
- You need to customize the data flow. Native connectors are notoriously inflexible, limiting you to using an individual tool’s view of the world to pass data back and forth. And since there often isn’t a 1:1 relationship between objects and entity types in common systems, you’ll get stuck in frustrating parent-child relationship paradigms. (See common problems for B2B customer data below).
iPaaS Connectors are Nimble but Fragile
Pros: iPaaS tools like Zapier, Boomi and SnapLogic are appealing because they offer a sea of connectors. Zapier alone connects to more than 5,000 different applications.
And they can offer plenty of different ways to move data between those tools.
Cons: But iPaaS is notorious for its fragility. If something breaks, it’s incredibly difficult to debug and figure out which of the 12 workflows scaffolding your Marketo-to-Salesforce-to-Outreach flow is to blame.
And iPaaS does little to counteract complexity. Many teams that deploy Zapier or Tray in use for core data flows have a great deal of “no-code debt” – aggregated complexity that has accrued over years of “just making another Zap” to fix issues when they pop up. While iPaaS can help with immediate bandaids, they not only are useless for long-term data strategy, but they actively prohibit it.
Related: Why Salesforce Shouldn’t Be Your Single Source of Truth
ETL and Reverse ETL Connectors, and the Warehouse Approach
More and more businesses are turning to “the modern data stack” approach to their customer data. This means, essentially, centralize all customer data in a warehouse.
In order to do this, ETL and “event streaming” tools must bring data to the warehouse, where data governance and master data tools and data modeling tools make it all make sense together, and then reverse ETL tools bring the data back into edge systems like your CRM.
Related: ETL vs ELT vs Reverse ETL Explained
Pros: You can customize it however you want.
Cons: Customizing it takes large teams and many tools and is inherently complex. Even if you can find ways to string together tools on the cheap, getting them all to sing the same song is no mean feat.
If you’d like to study this approach, check out “The Problem with the Modern Data Stack” for more detail.
The Syncari Way
You’ve probably gathered by now that Syncari is a platform that unifies customer data.
If you’ve been around warehouse-first or iPaaS approaches before, you know the limitations.
That’s why Syncari was built on the only multi-directional sync engine (check out the patent).
With embedded unification, ID stitching, cross-system merge and deduplication, custom actions, stateful sync across as many tools as you connect, data lineage, data health monitoring, and more than 50 connectors to the most common systems in use today, Syncari stands alone as the only purpose-built platform for unifying B2B customer data.
Sure, that’s not a ton of connectors. But a Syncari Synapse is worlds apart from a Zapier connected app. See above list of features.
No other tool lets you unify more than two systems simultaneously, with all your business logic mapped to your unique B2B customer data model.
And no other tool lets you do it without a single line of code.
(Of course, if you’d like to be able to query the data, or build custom connectors, that’s all possible too).
Difficult scenarios for B2B customer data:
There are several common problems that businesses have working with their customer data.
Parent-child relationships: difficult for both humans and computers
Parents and children have a hard time getting along, at times. This is true for B2B systems too.
The “parent-child relationship” problem is well-known to anyone who has managed a CRM like Salesforce or HubSpot. Or anyone who has tried to build attribution models at the Account level in Marketo or HubSpot.
This has to do with the limitations of each systems’ own “view of the world” – in other words, some tools strictly limit whether you can have one-to-one or one-to-many relationships between objects. For instance, in most tools, a contact cannot exist in multiple companies or accounts.
This is one reason it can be worthwhile to invest in a 3rd party solution to manage object relationships externally to any one system, with increased flexibility.
Existing contact job updates: keeping up with the changes
It’s one thing to get all the data merged and synced in all systems… and then life happens, and people at your customer accounts change jobs. Now you’ve got bouncing emails and an unknown value (where do they work now? Can they refer us?) that only LinkedIn is readily equipped to answer… And LinkedIn has a terrible API.
Most companies employ data enrichment tools to deal with these scenarios. But those have a lag time between when the change happens and when they detect it and can deliver the new information to you.
Also, since your primary unique identifier for contacts is their business email (most likely), it’s difficult to deduplicate with the same person at the new company. To most systems, they’ll just look like a different person entirely. “We are more than our professional email addresses” I guess.
This is one reason it can be worthwhile to deploy a 3rd party solution for ongoing merge and deduplication, that can go beyond deduplicating off of email and check combinations like “firstname + lastname + mobile phone” in order to resolve these issues.
Deduplication blockers: don’t stop that merge!
Inevitably, systems will produce duplicates. This is why you need to have a clear sense of your unique identifiers, and how to resolve issues when those are missing or non-specific.
Missing fields, generic phone numbers (like company phone number) and generic emails (like email groups and aliases) are frequent bad actors when it comes to uniquely identifying individuals. If you have only one person at a company, it’s not the end of the world. But you don’t usually close those deals, do you?
This is a good example of the relationship between accurate data and ease-of-going-to-market: if your contact information is a mess, you’ll have duplicates galore, and your sales team will hate working with your CRM. They’ll not only be less effective when they’re reaching out to a company, but they’ll be less inclined to update information in your CRM.
Deal automation: dragging contacts along too quickly
Typically, when a lead becomes an opportunity, and the opportunity progress through a series of stages, that lead/contact is dragged along through the same statuses.
That’s fine, as long as there aren’t any other contacts on the account. After all, the account is usually what is reaching those further stages. Other contacts on the account, like that CMO whose email you were able to find, or the head of data who got copied on an email – they’re not really part of the opportunity, are they?
Be careful about automating the status of your relationship with contacts who your team has yet to even engage.
Activity tracking: CYA stands for Cover Your Accounts
One notoriously frustrating thing to do in most CRMs is map contact activity from multiple contacts to the Account. It’s a wise idea, to make this map happen, since you can get full visibility across all sales reps and customer success managers as to what communication has been delivered to the account.
This is one reason it can be very worthwhile to invest in a 3rd party solution for tracking activity up to accounts, and reflecting that activity in CRM and CS tools alike.
Don’t wait to build your B2B customer data model.
It may take a good deal of work, but there are a few things to consider:
- How else will you know which connections and integrations to automate?
- How else will you know how to structure your teams to handle your customers’ experience in a streamlined way?
- How else will you solve major gaps in your customer journey?
If I had to guess, I’d bet that most poor conversion rates along the customer lifecycle happen in a cross-team transition, whether SDR to AE or AE to CS or pre-sales to post-sales user.
The first step in solving for the customer journey is to map it out, and this must include a map of how your data records and responds to your customers.


