




Powered by a unified data model, Syncari integrates and governs data with real-time precision — across APIs, pipelines, and agents.

Core Capabilities


Developer Extensibility
API-Driven. CI/CD Ready. Enterprise Scalable.

Agent Intelligence
MCP Server for Agents
Syncari’s Model Context Protocol (MCP) Server delivers governed, context-aware execution for every sync, workflow, and agent — so your systems always operate with a shared understanding of your data. What it enables:
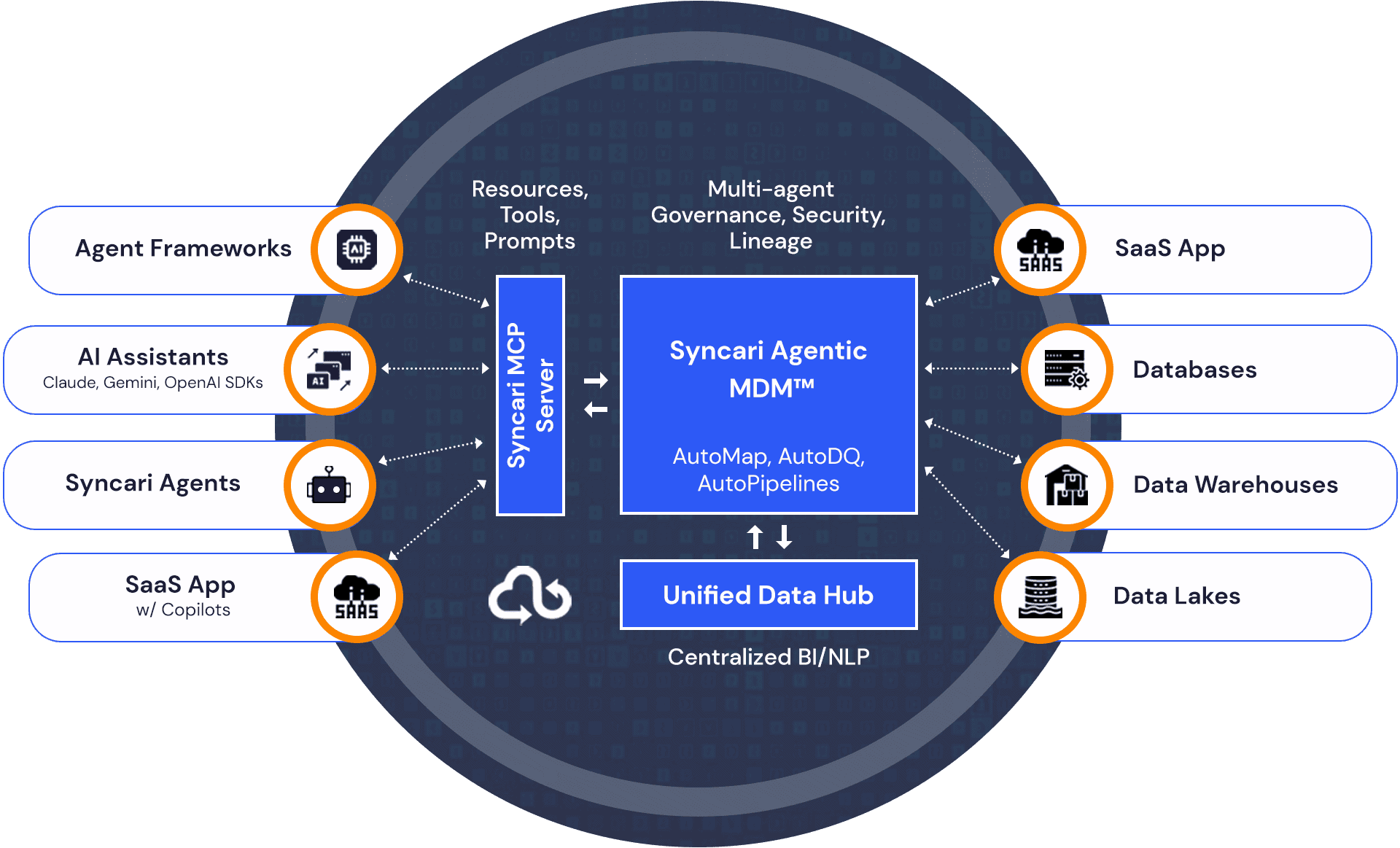
OEM Deployment
Integrate Syncari as a Core Engine in Your Product
Deliver a seamless experience under your brand. Customize UI, behavior, and system branding.
Provide scoped, per-tenant authentication to support multi-tenant SaaS environments.
Configure and govern integrations independently for each customer or deployment.
Operate behind a unified, abstracted schema layer for simplified API integration and consistent data outputs.
Leverage CLI, SDK, and DevDocs for full build-time and runtime integration flexibility.
Ideal for platform teams embedding governed sync into SaaS, CDPs, RevTech, FinTech, or vertical tools.

Syncari unifies data, automates workflows, and eliminates silos — in real time.


Make data the center of your universe with Syncari. Unlock real-time insights, seamless no-code integration, and total control to innovate faster, scale smarter, and outpace the competition.
Syncari provides data condition triggers, race condition management, and full data awareness. Unlike iPaaS solutions that focus on event-driven integration, Syncari ensures context-aware workflows with built-in data integrity checks across all connected systems.
Additionally, Syncari enables multi-source workflows within a single data pipeline, ensuring that data from multiple sources is harmonized, validated, and synchronized before being distributed to connected systems.
Traditional ETL tools primarily handle batch data movement and lack real-time, bi-directional synchronization. Syncari enables continuous data sync, schema adaptation, and intelligent automation, making it suitable for dynamic, evolving data environments.
Yes. Syncari can work alongside your existing middleware, iPaaS, and ETL solutions. Its API-first architecture and multi-directional sync engine enable seamless integration without requiring system replacements. Let Syncari be the context sharing data plane.
Organizations experiencing integration complexity, data inconsistencies, or high maintenance costs may benefit from consolidating onto Syncari. By replacing redundant middleware, Syncari can simplify data synchronization, improve governance, and reduce operational overhead.
Custom integrations require ongoing maintenance, version updates, and infrastructure management. Syncari eliminates these challenges by offering a scalable, no-code alternative that adapts to schema changes and evolving data models without requiring constant development effort.
Syncari provides self-service, no-code integration options that allow businesses to manage data syncs and workflows independently. Prebuilt connectors and reusable data pipelines enable faster implementation, improved adaptability, and enhanced customer experience through automated, consistent data flows.
For greater flexibility, Syncari supports headless deployment via embedded APIs, allowing direct interaction with custom workflows and integrations within user interfaces. This reduces IT dependency and improves scalability and customer retention.