
This is part 2 of my 5-part series about the cost of bad data. Read the previous post here.
The Economist calls data the oil of the 21st century and considering the quality at most companies, one has to imagine it laden with gunk. Companies spend $260 billion on analytics and yet only 55 percent of their data is available and only a fraction is suitable for analysis.³⁴ In a study of 75 enterprises by MIT, only 3 percent of data sets were within an acceptable range and 50 percent contained critical errors.⁵
Not only does bad data lead to wrong decisions, it also encumbers teams who spend as much as 50 percent of their time dealing with mundane data quality issues.⁶ Thomas Redman, the author of Data Driven, calls this the accommodation problem: Wherever there are errors, employees spend valuable time confirming with other sources and often neglect to correct it at the origin.
Bad data costs companies 15 percent of revenue in myriad and often compounding ways:
Marketing campaigns underperform. Marketing teams build inaccurate segments, launch ineffective campaigns, run the risk of being blacklisted by ISPs, and spend an average of 800 hours per year cleaning lists.⁷
Sales can’t sell. Salespeople spend too much time building lists and verifying emails and too little time actually selling. Today’s salespeople spend 64 percent of their time, or 900 hours per year per rep, on non-sales activities.⁸
Business teams accumulate risk. Fifty-five percent of data is dark— information the business doesn’t even know about, or can’t access—which exposes it to breaches and fines.⁹ By 2021, 25 percent of organizations with public APIs will have discontinued them due to security incidents, reports Gartner.¹⁰
Product teams build features that fail. The number one reason products fail is a lack of insight into the target audience or market.¹¹
HR over-staffs and can’t retain talent. HR teams over-hire based on inaccurate revenue projections, hire for the wrong roles, and can’t keep good employees from quitting.
Customer success teams upset customers. Companies damage customer loyalty and increase churn with redundant outreach to duplicate records, billing errors, reactive support, and shaky handoffs.
“Nothing wrecks sales productivity like hiring smart people and having them build lists.” – Scott Edmonds, Sales Advisor
Amidst all of this, teams continue to buy third-party data to cleanse and update existing records to the tune of $19 billion per year. What companies can’t seem to maintain in-house, they buy at great expense, while the underlying issues remain.¹²
The problem? Cloud connector chaos
The issue is the same legacy connections the team and I worked so hard to avoid at Marketo.
Businesses still connect SaaS applications with technologies designed during the dot-com crash without innovating them. Most companies have 12 to 15 apps plugged into their CRM, all of which use APIs that treat everything like a point-to-point connection, and every system like a silo, with no awareness of the overall data needs of the business. APIs can be smart, but the ways companies often use them are dumb.

Even if you keep most of your software purchases within one suite or “cloud” of tools, you still have data silos. Many marketing, HR, and back-office “clouds” are just marketing fluff. They’re groups of recently acquired companies that are insufficiently integrated to share data. Even if all your business units use the same CRM, there can be silos. Each organization often has its own disconnected instance, which prevents them from sharing data.
Each SaaS vendor also connects its app to others in its own unique way. If we stick with the data as oil analogy, your API-connected data ecosystem is an oil refinery where every pipe was built by different teams at different times. Some used the metric system, some imperial, some both. Some left instructions in Mandarin, others left none. Some pipes flow one way, but not the other. Some enrich the data. Others leak. The resulting data is sludge, and the problem is growing worse.
“Integration vendors are facing challenges in reconciling the semantic and syntactic differences in the thousands of APIs generated by SaaS and privately developed services.” – Gartner
The complexity of data ecosystems is rising exponentially
As the number of SaaS apps used by each company increases, the complexity of these ecosystems rises exponentially. This is known as the N-squared problem, or Metcalfe’s Law: When you add nodes to a network, the network grows exponentially more complex to manage. Consider the figure below.
Network connections = n(n-1)/2
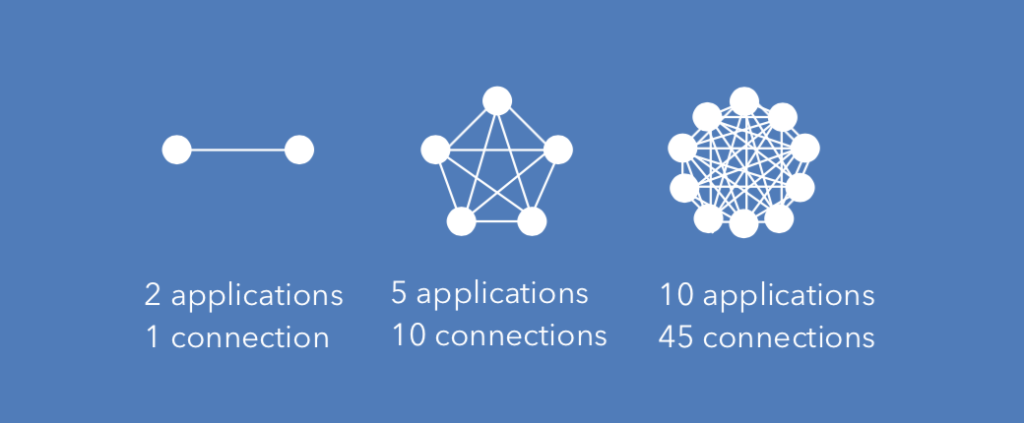
System complexity rises exponentially
When you have two nodes in a network, there’s one connector. When you jump to five nodes, you suddenly have ten connections. When you have 14 nodes—the average number of apps companies hook into their CRM—you have 91.
Companies don’t connect every system to every other system, but the principle holds. Lots of data is lodged in places other than the CRM or exists in duplicate across multiple systems. Good data is lost, overwritten, altered, omitted, expunged, and decayed.
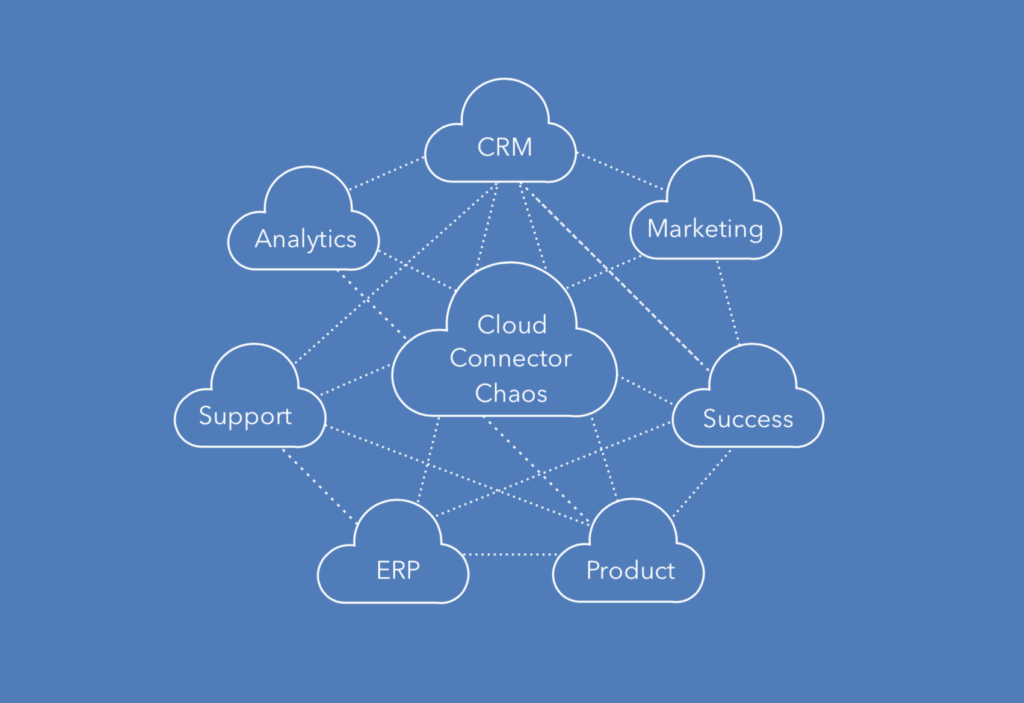
Most companies are in connection chaos
It gets even worse
Lots of business units now buy and launch cloud applications without IT’s involvement. In an effort to build friendlier UIs to appease these “citizen integrators,” many vendors now allow end users to rapidly reconfigure software settings and effectively change how the system stores and uses data. This means that at each of those endpoints, there are individuals like sales managers, accounts payable specialists, and engineers flipping switches and rewiring the company’s data architecture.
And, rather than making data quality better, the field of AI is rapidly making things worse.
Next up, we’ll talk about the devastating impact AI is having on most companies’ data.

https://syncari.com/
About the author: Nick is a CEO, founder, and author with over 25 years of experience in tech who writes about data ecosystems, SaaS, and product development. He spent nearly seven years as EVP of Product at Marketo and is now CEO and Founder of Syncari.
Sources
- IDC https://www.idc.com/getdoc.jsp? containerId=prUS44215218
- Splunk https://www.splunk.com/pdfs/dark-data/the-state-of- dark-data-report.pdf
- Harvard Business Review https://hbr.org/2017/09/only-3-of- companies-data-meets-basic-quality-standards
- Redman, Thomas. Data Driven https://hbr.org/product/data- driven-profiting-from-your-most-important-bus/an/1912-HBK- ENG
- ReachForce https://blog.reachforce.com/blog/the-time-spent- on-routine-tasks-how-much-time-is-your-team-wasting
- Forbes https://www.forbes.com/sites/kenkrogue/2018/01/10/ why-sales-reps-spend-less-than-36-of-time-selling-and-less- than-18-in-crm/#4ee28edbb998
- Splunk https://www.splunk.com/pdfs/dark-data/the-state-of- dark-data-report.pdf
- Gartner https://www.gartner.com/en/documents/3898763/ predicts-2019-democratization-of-it-requires-different-s
- CB Insights https://www.cbinsights.com/research/startup- failure-reasons-top/
- IAB https://www.iab.com/news/2018-state-of-data-report/


